經過上次預訓練模的解說後,今天就要解說預訓練語言模型中的基礎架構Transformer了。
相信各位都有聽過預訓練語言模型吧,但大概都不太了解有哪些模型?所以就來解說一下目前常見到的主流模型。
但是再說這些模型之前,就一定要提到Transformer啦。
Transformer是一種深度學習模型架構,最初用於自然語言處理和序列處理任務,藉由追蹤序列資料中的關係,學習上下文之間的脈絡及意義,關鍵創新是使用注意力(attention)或自我注意力(self-attention)的技術,可以允許模型同時處理序列中的所有位置,從而更好地捕捉長距離依賴關係。Transformer模型包括編碼器和解碼器,用於不同任務,並使用自注意力機制、前向神經網絡和位置編碼等進行建模。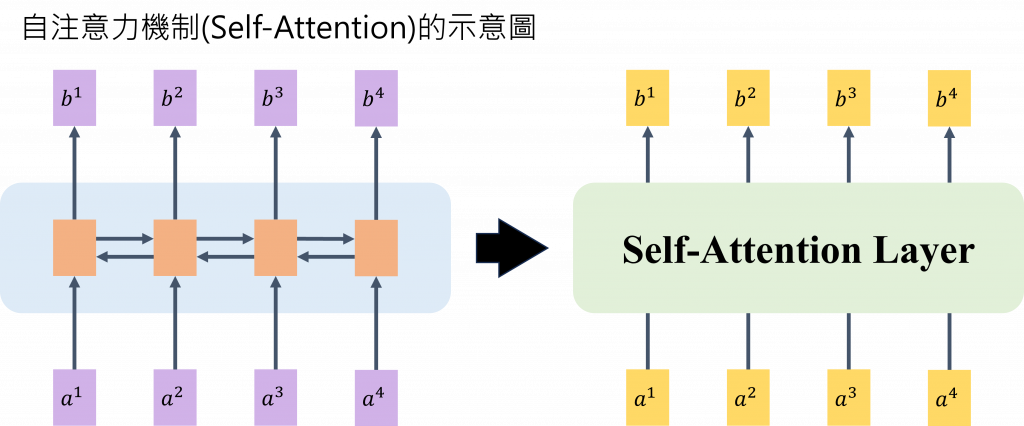
Transformer 模型主要由兩個部分組成:編碼器(encoder)和解碼器(decoder)
Transformer模型的encoder和decoder分別用於不同的任務,下面會針對他們進行介紹:
encoder:
decoder:
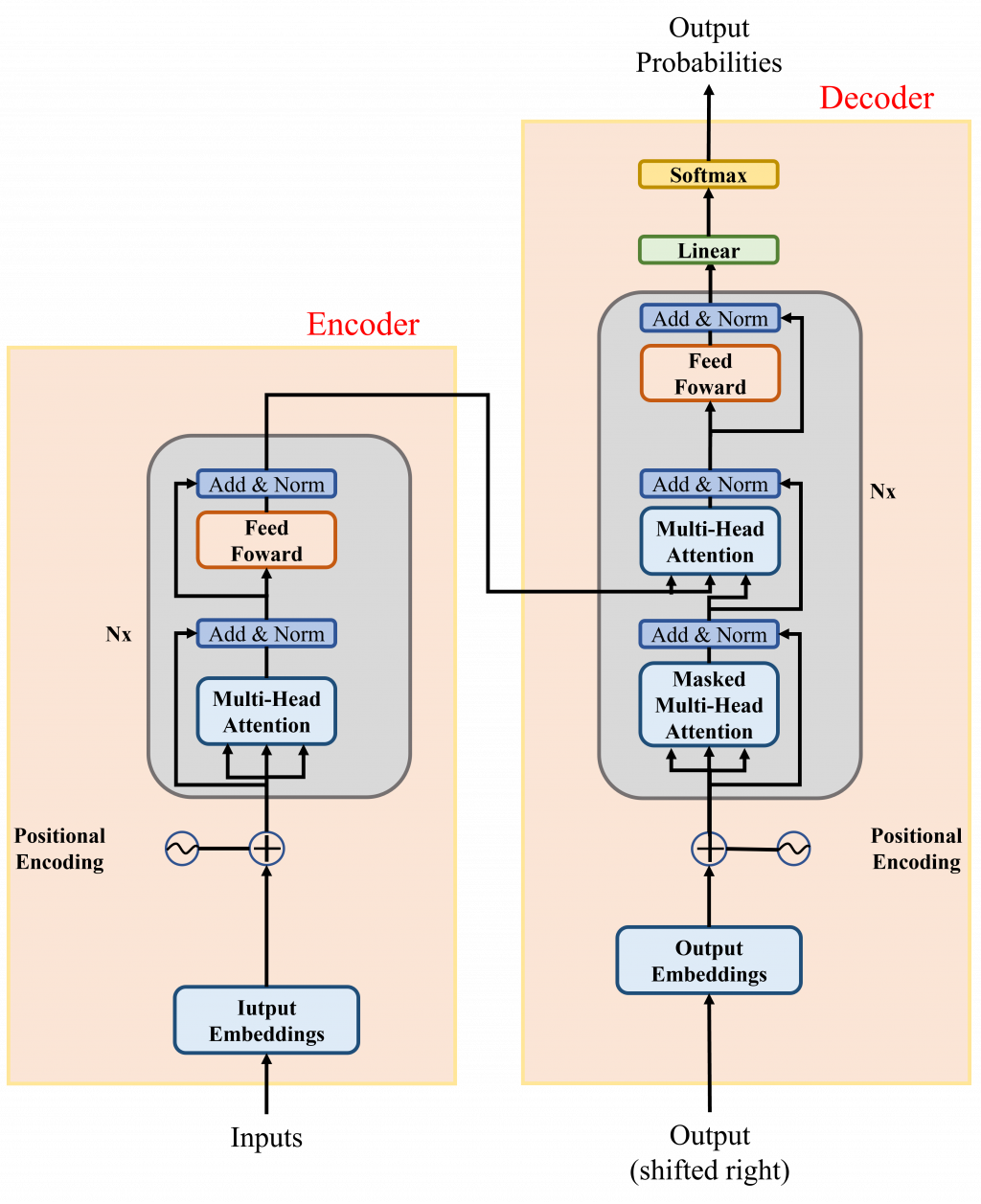
以上就是 Transformer的介紹了,接著我們會將會介紹Transformer的衍生模型有哪些了。
Transformer模型的成功啟發了許多衍生模型,這些模型基於不同的架構和應用,可以根據encoder和decoder的不同組合進行分類。
以下是一些主要的Transformer衍生模型:
基於Encoder的模型:
基於Decoder的模型:
結合Encoder和Decoder的模型:
以上就是一些較為常見的Transformer模型,每個模型在不同的NLP任務中都有其獨特的應用和優勢。這些模型的發展不斷推動著自然語言處理和序列處理領域的進步。
今天只有單純針對Transformer進行介紹,並解說了以Transformer為基礎架構的預訓練模型。
明天將會開始解說不同的預訓練模型,並實際使用PyTorch來針對特定下游任務的數據集來微調該模型的實作。

